|

Please let me know by return mail if you
want to be removed from my mail list .
See my Newsletter 201410 for my progress this year
working towards restoring the classic quantitative analytical method of physics
to the understanding of planetary temperature and climate including particularly
my presentation of The Basic Basics at the Heartland Institute's Las Vagas Climate Conference
This letter is almost exclusively about progress on and aspects of 4th.CoSy
Expect a new upload the beginning of the Year .
working towards restoring the classic quantitative analytical method of physics
to the understanding of planetary temperature and climate including particularly
my presentation of The Basic Basics at the Heartland Institute's Las Vagas Climate Conference
This letter is almost exclusively about progress on and aspects of 4th.CoSy
Expect a new upload the beginning of the Year .
I got out to Forth Day at Stanford again this fall . Had some useful meetings and actually got 4th.CoSy up on a couple of pioneers' machines .
Given that motivation , I'm getting some very basic and essential work done on CoSy . For instance , I have managed to get along all this time without having an actual insertion word ( I've decided to name at! ) . Here's it's current definition in Ron Aaron's Reva.Forth CoSy is built in :
: at! ( v0 i v -- v ) | insert elements of v0 at locations i in vThe .s ." | simple " cr is in it for debugging .
>aux 2p ( L@ lst cr R@ lst cr aux@ lst cr )
aux@ Type@ 0if L@ i# 0do L@ i i@ aux@ R@ i i@ ix rplc loop 2P aux> ;then
.s ." | simple " cr R@ i# 0do L@ i i@ aux@ R@ i i@ i! loop 2P aux> ;
--
The slurping ( reading in ) of the source files in the example below in a comment on the Silicon Vally Forth Interest Group list took me most of a day to get working because of an excessively meandering path getting down to the core issue that I was splitting on "lf rather than "nl and was leaving a trailing "cr the names which slurp^ couldn't understand .
-------- Forwarded Message --------
Intel is going heavily 3D , particularly in memory . A good chunk of the afternoon at their recent Investor's Day was about the disruptive density and cost-reduction they see in flash . They are doing like 32 layers ( I'm not sure of what ) .
Irvine Sensors was doing stacked chip "retinas" more than a decade ago . Heat becomes an issue .
16 * 64 APL characters can express a LOT of algorithm .
That's why I've been motivated to create an APL informed vocabulary of dynamic recursive lists in Forth .
I wondered how many screens of Forth a screen of APL was worth , and I found what I've gotten done done is about 113 , simply counting characters :
( Sorry for the self-indulgence , but it was a useful exercise . )
I remember when they placed big mylar balloons in orbit , as passive Echo satellites . We all went out to see them pass over as they were quite visible . I see they managed to get the first satellite in Clarke , geostationary , orbit by 1964 .
Bob A
--
On 2014-12-18 11:35, David L. Jaffe wrote:
| Subject: | Re: [svfig] <<NSF>> Smaller, faster, greener "high-rise" 3D chips are ready for Big Data |
|---|---|
| Date: | Fri, 19 Dec 2014 08:12:56 -0700 |
| From: | Bob Armstrong <bob@cosy.com> |
| To: | Silicon Valley Forth Interest Group <svfig@zork.net> |
Intel is going heavily 3D , particularly in memory . A good chunk of the afternoon at their recent Investor's Day was about the disruptive density and cost-reduction they see in flash . They are doing like 32 layers ( I'm not sure of what ) .
Irvine Sensors was doing stacked chip "retinas" more than a decade ago . Heat becomes an issue .
16 * 64 APL characters can express a LOT of algorithm .
That's why I've been motivated to create an APL informed vocabulary of dynamic recursive lists in Forth .
I wondered how many screens of Forth a screen of APL was worth , and I found what I've gotten done done is about 113 , simply counting characters :
s" dir CoSy\\*.f /b /s " shell> >t0 | get source file names ,But it would be fairer to count lines :
t0 "nl toksplt -1 _i cut >t0> | split on nl . drop empty last row
(
s" C:\4thCoSy\CoSy\AltStackOps.f"
s" C:\4thCoSy\CoSy\CoSy.f"
s" C:\4thCoSy\CoSy\CSauxstack.f"
s" C:\4thCoSy\CoSy\Derived.f"
s" C:\4thCoSy\CoSy\FloatsPlus.f"
s" C:\4thCoSy\CoSy\Furniture.f"
s" C:\4thCoSy\CoSy\Head#change.f"
s" C:\4thCoSy\CoSy\Job.f"
s" C:\4thCoSy\CoSy\math.f"
s" C:\4thCoSy\CoSy\RecurInterp.f"
s" C:\4thCoSy\CoSy\SaveRestore.f"
s" C:\4thCoSy\CoSy\SaveRestoreNew.f"
s" C:\4thCoSy\CoSy\Tui.f"
s" C:\4thCoSy\CoSy\util.f"
s" C:\4thCoSy\CoSy\Danny\simple-button.f"
s" C:\4thCoSy\CoSy\Danny\simple-button2.f"
)
t0 { slurp^ rho } eachM> ,/ | read each file and return their lengths
i( 1382 53293 2554 1046 4312 6431 1615 7112 1292 3758 4580 5310 9231 12157 819 1109 )i
R0 +/ | add them up
116001
R0 i>f 64. _f %f | divide result by 64
1812.51562
R0 16. _f %f | divide by 16
113.28222
t0 { ^slurp^ "lf toksplt rho } eachM> ,/ +/ | split each file into lines and count themSo , depending on whether you count total characters or actual lines as written , this bit of APLish takes about 110 or 240 screens to support , not counting Ron Aaron's Reva Forth they are built in .
3893
R0 i>f 16. _f %f
243.31250
( Sorry for the self-indulgence , but it was a useful exercise . )
I remember when they placed big mylar balloons in orbit , as passive Echo satellites . We all went out to see them pass over as they were quite visible . I see they managed to get the first satellite in Clarke , geostationary , orbit by 1964 .
Bob A
--
On 2014-12-18 11:35, David L. Jaffe wrote:
IBM did some work in on stacked chips for the memory in the IBM 5100 in 1973 - that predated their PC products http://en.wikipedia.org/wiki/IBM_5100the neat thing for me is that you could literally switch from BASIC to APLvia a front-panel toggle----- Original Message -----From: Jason DamischSent: Thursday, December 18, 2014 9:44 AMSubject: [svfig] <<NSF>> Smaller, faster, greener "high-rise" 3D chips are ready for Big Data
This from Stanford, our gracious hosts. :^)
Sorta reminds me of Green Arrays.
Jason
_______________________________________________
http://zork.net/mailman/listinfo/svfig
neither public nor private,
this membership of correspondence
_______________________________________________
http://zork.net/mailman/listinfo/svfig
neither public nor private,
this membership of correspondence
Comments from a
couple of emails concerning speed
Speed has never been a particular interest to me . It's a nice , and
comes with the APL structure . But my central interest is the
ability to express and play with logically parallel algorithms .
AND very much the personal interface so I can take care of the
business of life as I have phrased it , and work effectively thru
problems of interest to me , such as a planetary model .
The big speed advantage of Kdb over SQL is that SQL is a step too academic and suppresses order . It's based on the notions of unordered sets . Kdb does not suppress order so if you select some subset of data you know it will be returned in the order of the original data . I mentioned this in one of our conversations . This is why Kdb concentrates so much on time series analytics which are very clumsy to specify in SQL lacking a concept of order .
I played with the Kdb vocabulary built on top of K but found it clumsier than making my own functionally similar vocabulary . I ran into a link on http://www.hakank.org/k/ to my whole vocabulary I forgot I had posted at http://cosy.com/K/CoSy/K_CoSy.htm . All the database functions are prefixed with DT for DictionaryTable . All my ledgers are kept in such tables .
I'm sure Jim [ Brown ] knows a lot more about this stuff , especially performance , than I do .
The standard email file structure strikes me as a mess . I spent a bunch of time doing various things with email and spam filter logic in K but haven't touched it since turning to work on 4th.CoSy .
The first speed advantage of Kdb is , like a lot of properly structured DBs in APL , its columnar structure back when other people were using "horizontal" records . They used to call the columnar structure "inverted" .Q2. Can we eliminate the database, especially relational, structured database and use some thing else? Kdb is array based and it not only maintains but delivers additional speed, will it help? Any suggestions? B-trees, Quad-trees, combination of Vec and Ravel, shard technology?
The big speed advantage of Kdb over SQL is that SQL is a step too academic and suppresses order . It's based on the notions of unordered sets . Kdb does not suppress order so if you select some subset of data you know it will be returned in the order of the original data . I mentioned this in one of our conversations . This is why Kdb concentrates so much on time series analytics which are very clumsy to specify in SQL lacking a concept of order .
I played with the Kdb vocabulary built on top of K but found it clumsier than making my own functionally similar vocabulary . I ran into a link on http://www.hakank.org/k/ to my whole vocabulary I forgot I had posted at http://cosy.com/K/CoSy/K_CoSy.htm . All the database functions are prefixed with DT for DictionaryTable . All my ledgers are kept in such tables .
I'm sure Jim [ Brown ] knows a lot more about this stuff , especially performance , than I do .
The closest thing to a "database" in CoSy is the dictionary structure modified from Arthur's dictionaries . They are essentially just paired lists of symbols and values . Arthur added a third column of attributes or meta data which I understand was influenced by similar designs in some Lisps . I have found metadata to be so important that I have restructured the headers of all CoSy objects to allow a link to metadata , which in general will itself be a dictionary .Q3. What is the underlying database of CoSy? Emails do not utilize file technology: how does email get organized and preserved?
The standard email file structure strikes me as a mess . I spent a bunch of time doing various things with email and spam filter logic in K but haven't touched it since turning to work on 4th.CoSy .
I read an article long ago titled something like "Why Forth is not slow" . It had an analysis that the path to the machine was generally quite shallow , sort of a log of the number of words called . sort of thing . But the general approach of Forthers is that if something really is speed critical , it is defined in assembler -- which can simply be inlined with defined Forth . This is made very easy in Reva Forth . Here's an example you will find in theI will keep you in the loop and as soon as possible I will provide further details. How fast is FORTH? How fast is CoSy? How fast is K? How do they handle DNA stuff?
4thCoSy/CoSy/util.f file :| \/ | Iverson logic | \/ |Several of the real x86 machine language guys who contributed to Reva when it was being fleshed out would simply post the hex sequences . Several times I had to ask for translations to the actual assembly so I could have a clue . This is a result returning equals . Ron originally only had the conditionals like =f until I asked for an actual result returning function . It shows how far from "functional" thought the Forth world can be .
: =I ( n1 n2 -- flag ) | Original : =I =if 1 else 0 then ;
inline{ 3b 06 ad 0f 94 c0 0f be c0 } ;
| from Jukka , http://ronware.org/reva/viewtopic.php?pid=4613#p4613
| the assembly:
| cmp eax,[esi] ; standard stuff
| lodsd ; ditto
| sete al ; sets al to 1 if zero flag set otherwise sets it to 0
| movsx eax,al ; expands al to eax filling the rest with zeros
| was inline{ 3b 06 ad b8 0 0 0 0 75 01 40 } ;
| from Ron , http://ronware.org/reva/viewtopic.php?pid=4595#p4595
| Annotated assembler from Cellarguy :
| asm{
| cmp eax,[esi] ; compare TOS,NOS to set the zero clear flag
| lodsd ; poor-man's drop, or:
| ; 'I don't care what I pull into tos... ( = drop )
| mov eax,00000000 ; ...because I'm over-writing it anyway' ( with 0 ).
| jnz .done ; now we check that flag we set.
| inc eax ; if flag was set add 1 to the 0 and leave that ( -- 1)
| .done: ; else just leave the 0 ( -- 0 )
| } ;
|
| was : =I =if 1 ;; then 0 ; | Helmar 2005-10-15 13:19:28
One further point I should mention . Each of those dictionary items , eg , Date , is has an attribute ( meta ) dictionary associated with it . In K , as I've said , this is kept in a third column in the dictionary . In 4th.CoSy I have changed this structure by adding one cell to object headers so each object can have an associated meta dictionary .
In the example here , the attribute on each of the items , eg , Date , is a function to sort the table on the heading clicked . On the whole table , QW , it's and entire dictionary of functions to be executed for such things as copying and inserting , and information like date of last modification , associated account numbers , etc .
--
--
I felt I wasn't as clear about the structure of K databases as I might have been . ( CoSy's essentially the same . )
A dictionary is a pair of lists ( names ; values )
A database is a dictionary where all the values are lists of the same length . Here's a little one that happens to be sitting around open on my machine right now .
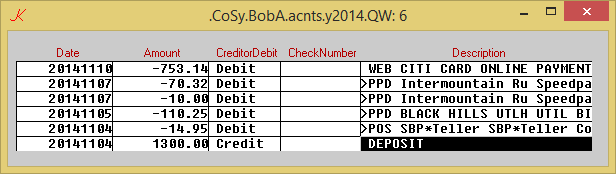
It's a dictionary of 5 items the values of each of which are lists of 6 items .
All for now | 20141223.154847 |
See related 4th.CoSy Download & Disqusion
 |
|
||||